Numerical Optimization
Poisson Boundary Control with PETSc/TAO
At a Glance
| Questions | Objectives | Key Points |
| 1. What is PDE-constrained optimization? | Understand the basic principles | The PDE is imposed as an equality constraint for the optimization problem |
| 2. What is the reduced-space formulation? | Separate the optimization and the PDE solution | The PDE states are removed from the optimization problem using the implicit function theorem |
| 3. What is adjoint-based sensitivity analysis? | Compute gradients for functionals that depend on the solution of a PDE | The adjoint method can efficiently provide gradient information when the objective function relies on the solution of expensive PDEs |
Note: To run the application in this lesson
cd HandsOnLessons/boundary_control_tao
make
./boundary_control inputs -tao_monitor -tao_ls_type armijo -tao_fmin 1e-6
Brief Introduction to PDE-Constrained Optimization
PDE-constrained optimization algorithms seek to find the input variables or parameters (referred to as “control”, “design” or “optimization” variables) that minimize (or maximize) a functional that depends on the solution of a partial differential equation (PDE). A general PDE-constrained optimization problem is stated as \[\min_{p, u} \quad f(p, u) \quad \text{subject to} \quad R(p, u) = 0,\]
where \(p \in \mathbb{R}^n\) are the optimization variables, \(u \in \mathbb{R}^m\) are the PDE states, \(f(p, u): \mathbb{R}^{n \times m} \rightarrow \mathbb{R}\) is the objective function, and \(R(p, u): \mathbb{R}^{n \times m} \rightarrow \mathbb{R}^m\) are the state equations that represent the discretized PDE.
The above optimization statement is called the “full-space” method for PDE-constrained optimization, where the PDE solution variables \(u\) are solved simultaneously with the optimization variables \(p\). Consequently, the size of the optimization problem is \(n + m\).
In the “reduced-space” formulation, the PDe constraint is removed from the optimization problem using the implicit function theorem, such that \[\min_p \quad f(p, u(p)),\]
where the state or solution variables \(u\) are now expressed as an implicit function of the optimization variables \(p\). In practice, this means that every evaluation of the objective function \(f(p, u(p))\) at a new \(p\) point requires a complete solution of the state equations \(R(p, u) = 0\) in order to compute the solution \(u(p)\) that corresponds to that \(p\) point. Consequently, the function evaluation becomes significantly more expensive, at the trade-off that the size of the optimization problem shrinks to \(n\).
The reduced-space formulation can also be re-written as \[\min_p \quad f(p, u(p)) \quad \text{governed by} \quad R(p, u) = 0,\]
where the “governed by” notation describes the governing equations that relate the solution variables \(u\) to the optimization variables \(p\), but are not imposed as constraints in the optimization problem.
In this lesson, we focus on gradient-based optimization methods – methods that utilize information about the sensitivity of the objective function with respect to its inputs. We begin by exploring the optimality conditions for this class of algorithms as applied to the PDE-constrained problem.
Optimality Conditions
For full-space PDE-constrained optimization, the first-order optimality conditions are derived first by forming the Lagrangian \[\mathcal{L}(p, u, \lambda) = f(p, u) + \lambda^T R(p, u),\]
where \(\lambda \in \mathbb{R}^m\) are the Lagrange multipliers associated with the PDE constraint. Differentiating the Lagrangian with respect to all of its inputs yields the first-order optimality conditions (also called the Karush-Kuhn-Tucker conditions) that must be satisfied by the optimal solution: \[\nabla_p \mathcal{L} = \frac{\partial f}{\partial p} + \lambda^T \frac{\partial R}{\partial p} = 0,\] \[\nabla_u \mathcal{L} = \frac{\partial f}{\partial u} + \lambda^T \frac{\partial R}{\partial u} = 0,\] \[\nabla_\lambda \mathcal{L} = R(p, u) = 0.\]
Newton-type optimization algorithms apply the Newton’s method to the first-order optimality conditions to produce the Karush-Kuhn-Tucker (KKT) system,
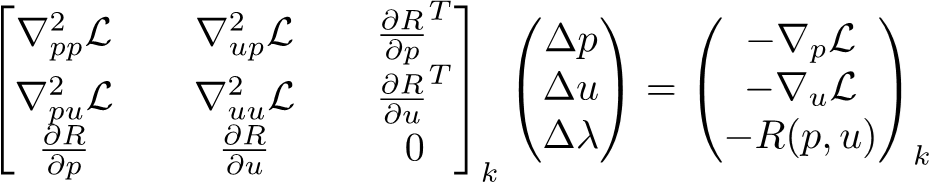
which is solved at every Newton iteration to produce the step direction \((\Delta p, \Delta u, \Delta \lambda)\). The step is then globalized using a line search or a trust region framework in order to avoid stationary points that are not the minimum. This approach converges the PDE states simultaneously with the optimization variables. This means that the PDE solution and the optimization are tightly coupled and the PDE constraint is not satisfied at intermediate steps.
The reduced-space variant of the above problem solves the KKT system with the following steps:
Solve \(\nabla_\lambda \mathcal{L} = R(p, u) = 0\) at each new \(p\) for \(u(p)\). This is called the “state solution”, i.e.: calculating the PDE state at \(p\).
Substitute \(p\) and \(u(p)\) into \(\nabla_u \mathcal{L}\) amd solve \(\left( \frac{\partial R}{\partial u} \right)^T \lambda = -\frac{\partial f}{\partial u}\) for \(\lambda(p, u)\). This is called the “adjoint solution” and the Lagrange multipliers are called the adjoint variables in the reduced-space formulation.
Substitute \(p\), \(u(p)\) and \(\lambda(p, u)\) into \(\nabla_p \mathcal{L}\) and solve \(\nabla_{p}^2 \mathcal{L} \Delta p = -\nabla_p \mathcal{L}\) for the step direction \(\Delta p\).
Note that the reduced-space steps avoid the computation of second derivative information in \(\nabla_{pu}^2 \mathcal{L}\) and \(\nabla_{uu}^2 \mathcal{L}\). Additionally, the PDE solver and the optimization algorithm are decoupled from each other. This comes at the cost of performing a full PDE solution for every objective function evaluation.
Using TAO
Toolkit for Advanced Optimization (TAO) is a package of optimization algorithms and tools developed at Argonne National Laboratory and distributed with the Portable Extensible Toolkit for Scientific Computing (PETSc) library. It is primarily intended for continuous gradient-based optimization, and supports PDE-constrained problems using the reduced-space formulation.
Below is a TAO main file template that can be adapted to any PDE-constrained problem:
#include "petsc.h"
typedef struct {
int n; /* number of optimization variables */
} AppCtx;
PetscErrorCode FormFunctionGradient(Tao tao, Vec P, PetscReal *fcn,Vec G,void *ptr)
{
PetscErrorCode ierr;
AppCtx *user = (AppCtx*)ptr;
/* Compute objective function and store in fcn */
/* 1. Compute the states U(P) for the given P vector (i.e.: solve the PDE) */
/* 2. Use P and U(P) to compute the objective function */
/* Compute gradient and store in G */
/* 1. Solve the adjoint system for the adjoint variables lambda(P, U(P)) */
/* 2. Compute the gradient G = \nabla_p f using P, U(P), lambda(P, U(P)) */
return 0;
}
int main(int argc, char *argv[])
{
PetscErrorCode ierr;
AppCtx user;
Tao tao;
/* Initialize problem and set sizes */
ierr = PetscInitialize( &argc, &argv,(char *)0,help );if (ierr) return ierr;
ierr = VecCreateMPI(PETSC_COMM_WORLD, user.n, user.N, &X);CHKERRQ(ierr);
ierr = VecSet(X, 0.0);CHKERRQ(ierr);
ierr = TaoCreate(PETSC_COMM_WORLD, &tao);CHKERRQ(ierr);
ierr = TaoSetType(tao, TAOBQNLS);CHKERRQ(ierr);
ierr = TaoSetInitialVector(tao, X);CHKERRQ(ierr);
ierr = TaoSetObjectiveAndGradientRoutine(tao, FormFunctionGradient, (void*) &user);CHKERRQ(ierr);
ierr = TaoSetFromOptions(tao);CHKERRQ(ierr);
ierr = TaoSolve(tao);CHKERRQ(ierr);
ierr = VecDestroy(&X);CHKERRQ(ierr);
ierr = TaoDestroy(&tao);CHKERRQ(ierr);
ierr = PetscFinalize();
TAO calls the user-provided FormFunctionGradient() routine whenever the optimization algorithm needs to evaluate the objective and its gradient. The AppCtx structure contains any data the user has to preserve and propagate through for these computations.
Example Problem: Boundary Control with the 2D Laplace Equation
The inverse problem for the boundary control case is given as \[\min_p \quad \frac{1}{2}\int_0^1 (u(1, y) - u_{targ})^2 d y,\] \[\text{governed by} \quad \frac{\partial^2 u}{\partial x^2} + \frac{\partial^2 u}{\partial y} = 0 \quad \forall \; x, y \in (0, 1),\] \[p = \left[u(x, 0), u(0, y), u(x, 1) \right]^T \quad \text{and} \quad \frac{\partial u}{\partial x}\Bigr|_{x=1}.\]
where \(u_{targ}\) is a target solution that we want to recover by controlling the bottom, left and top Dicihlet boundary terms with the optimization variables in \(p\). In this example, we set the target solution to \(u_{targ} = 4(y - 0.5)^2 - 0.5\).
| Representative Domain | Target Solution on Right Boundary |
|---|---|
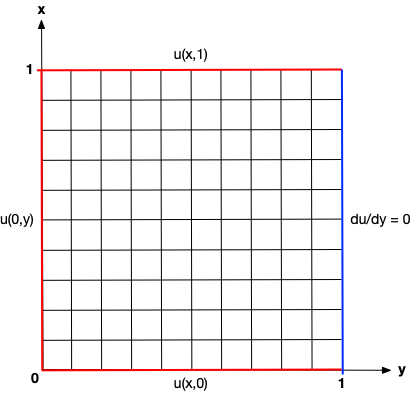 {:width=”130%” {:width=”130%” | 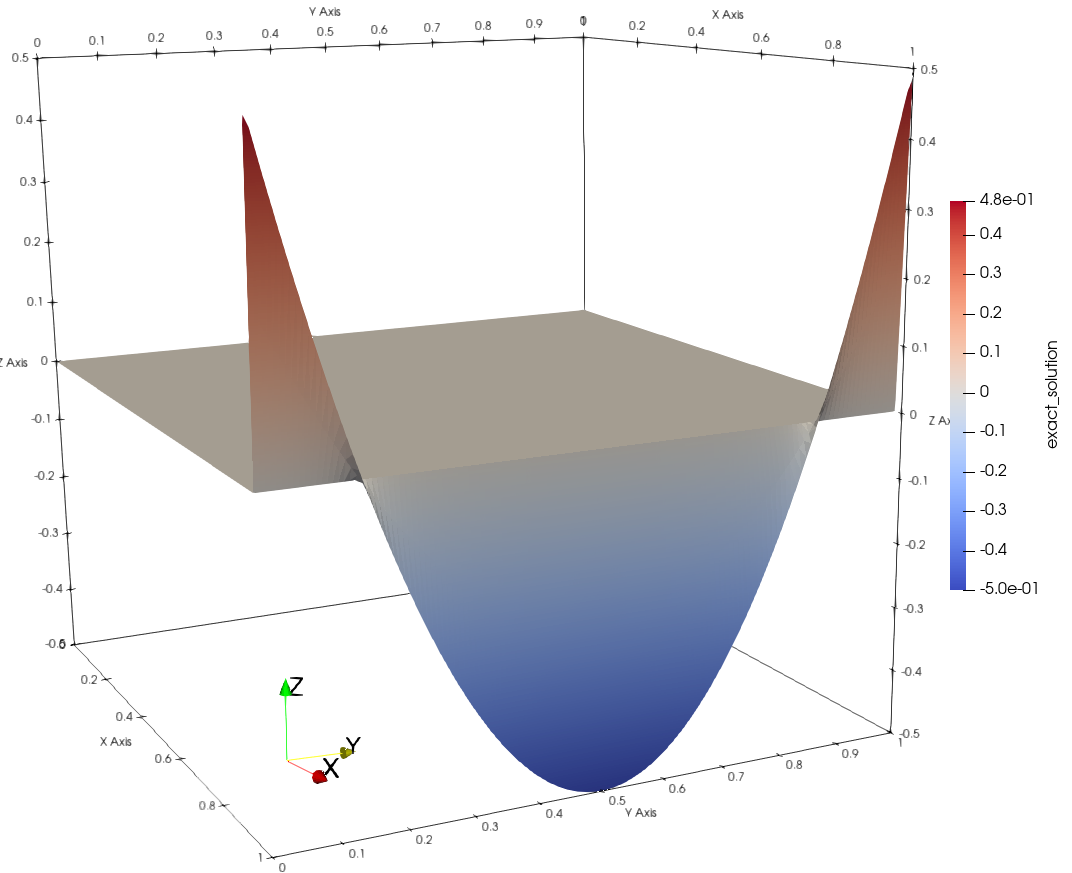 |
We use AMReX to solve the governing equation. The default domain is a 128x128 cell square and the edge size can be changed with the option flag -nx <integer>. Since the Laplace equation is self-adjoint, i.e. the Jacobian is symmetric, we can perform the adjoint solution by changing the right-hand-side vector for the forward solution.
The source code for this problem is available on GitHub under AMReX-Codes/ATPESC-codes/TAO-of-AMReX. The problem can be compiled and run with:
cd HandsOnLessons/boundary_control_tao
make
./boundary_control inputs -tao_monitor -tao_ls_type armijo -tao_fmin 1e-6
In this example, we will run the problem with different TAO configurations using command line options. Below is an overview of some of the available flags. For a complete list, please refer to the TAO User Manual.
| Flag | Available Options | Description |
|---|---|---|
-tao_type | bncg, bqnls | Change the TAO algorithm type |
-tao_ls_type | unit, armijo, more-thuente | Change the TAO line search type |
-tao_gatol | 1e-12 (real number) | Set the absolute gradient norm tolerance for convergence |
-tao_fmin | 1e-6 (real number) | Set the absolute function value tolerance for convergence |
-tao_monitor | N/A | Activates the iteration monitor for the TAO solution |
-tao_ls_monitor | N/A | Activates the line search monitor within each TAO iteration |
-nx | 128 (integer) | Set the number of cells on each edge of the square domain |
-fd | N/A | Disable the adjoint method and turn on the finite difference method for the gradient |
-plot | N/A | Enable writing of AMReX plot files |
Results
Running the above command produces the output below with information from TAO about the optimization.
MPI initialized with 1 MPI processes
AMReX (447467a2ca90) initialized
0 TAO, Function value: 0.00564792, Residual: 0.000749689
1 TAO, Function value: 0.00559275, Residual: 0.000744637
2 TAO, Function value: 0.000888762, Residual: 0.00015535
3 TAO, Function value: 0.000605835, Residual: 0.000115997
4 TAO, Function value: 0.000233747, Residual: 3.97986e-05
5 TAO, Function value: 0.000162946, Residual: 3.63787e-05
6 TAO, Function value: 6.59668e-05, Residual: 1.59724e-05
7 TAO, Function value: 4.40513e-05, Residual: 6.76306e-06
8 TAO, Function value: 2.44612e-05, Residual: 2.77668e-05
9 TAO, Function value: 2.2582e-05, Residual: 2.69655e-05
10 TAO, Function value: 1.50213e-05, Residual: 1.53602e-05
11 TAO, Function value: 1.16378e-05, Residual: 1.13325e-05
12 TAO, Function value: 9.13617e-06, Residual: 4.94145e-06
13 TAO, Function value: 8.49373e-06, Residual: 1.74395e-06
14 TAO, Function value: 8.39324e-06, Residual: 1.52181e-06
15 TAO, Function value: 8.31419e-06, Residual: 1.89774e-06
16 TAO, Function value: 7.63232e-06, Residual: 5.39182e-06
17 TAO, Function value: 6.67578e-06, Residual: 8.13022e-06
18 TAO, Function value: 4.59113e-06, Residual: 1.10091e-05
19 TAO, Function value: 4.51694e-06, Residual: 1.61728e-05
20 TAO, Function value: 2.03898e-06, Residual: 9.35813e-06
21 TAO, Function value: 1.17464e-06, Residual: 5.05618e-06
22 TAO, Function value: 8.64949e-07, Residual: 2.68442e-06
TaoSolve() duration: 751834 ms
[The Pinned Arena] space (MB) used spread across MPI: [8 ... 8]
AMReX (447467a2ca90) finalized
In this case, we have specified an absolute function value tolerance of \(10^{-6}\) (with -tao_fmin 1e-6) and we can see in the output that the optimization terminates at this tolerance. To validate this further, we can run the problem with the -tao_converged_reason argument and inspecting the printed convergence reason: TAO solve converged due to CONVERGED_MINF iterations 21.
We can also visualize the AMReX solution using Paraview, with the initial solution (\(u_0 = 1.0\)) on the right and the final solution on the left. The final solution captures the target solution at the right edge (\(x = 1\)) accurately by manipulating the Dirichlet boundaries on the bottom (\(y=0\)), left (\(x=0\)) and top (\(y=1\)) edges. Note that the missing line in the final solution surface is a visualization artifact.
| Initial Solution | Final Solution |
|---|---|
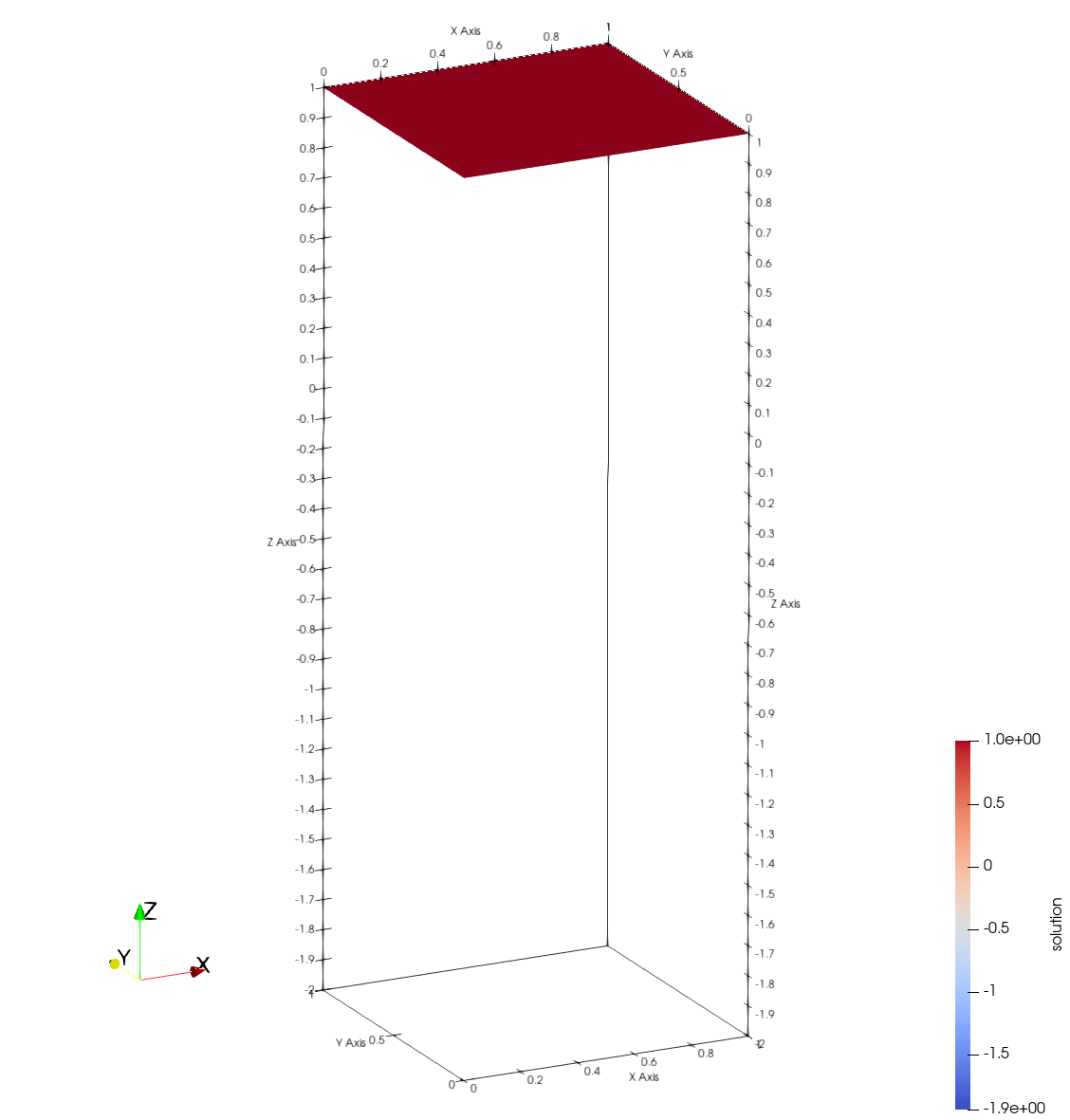 | 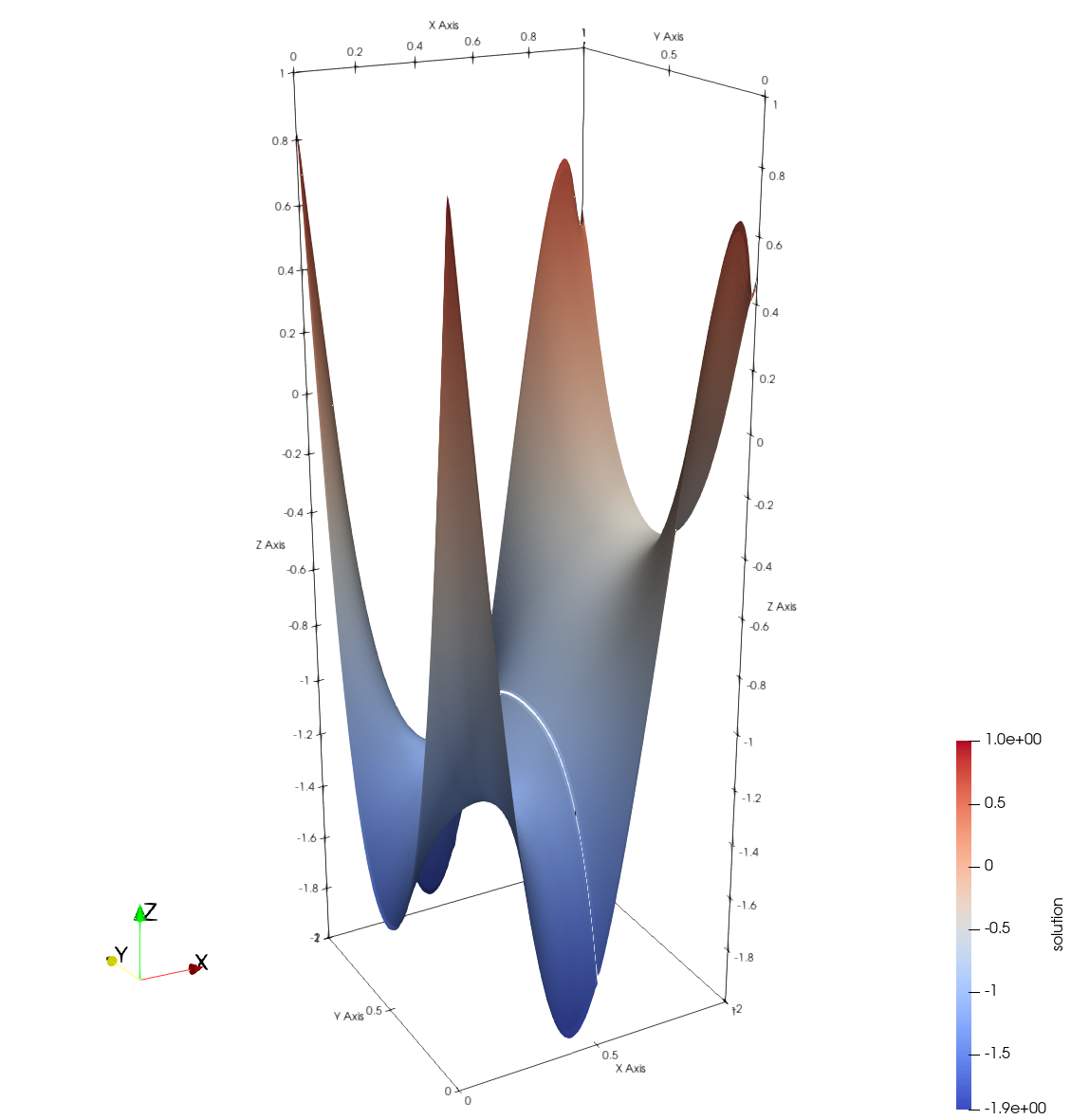 |
Hands-on Activities
Change problem size with
-nx <size>(default is 128) and evaluate its impact on performance. Now disable the adjoint solution and enable the finite difference gradient with-fd. Change problem size again and evaluate both convergence and iteration speed.Run the problem in parallel using
mpiexec -np 4 ./boundary_control .... AMReX and PETSc can seamlessly scale up the problem without changing the source code.Change TAO algorithm to the nonlinear conjugate gradient method using
-tao_type bncg. Compare convergence with the default method (bqnls– quasi-Newton line search). Change the line search type (using-tao_ls_type) and convergence tolerances (using-tao_fminand-tao_gatol) to help the problem converge.Change the initial starting point and see if the solution converges to a different local minimum. The default starting point is Dirichlet values set to \(1.0\) for all controlled boundaries (bottom, left and top). You can either choose a different constant value, or try to impose a more complicated starting point by manipulating the vector data element-by-element.
Change the target solution in
boundary_control.cpp. You can define any 1D function forutargwith the y-coordinate as the input variable.
amrex::Real TargetSolution(amrex::Real* coords)
{
amrex::Real y = coords[1];
amrex::Real utarg = 4.*(y-0.5)*(y-0.5) - 0.5;
return utarg;
}
For each of these tasks, you can inspect the solution at each iteration by opening the AMReX plot files in VisIt or ParaView. If you use ParaView, you must use the latest v5.7.0 RC1 version with support for the AMReX grid format. 2D solutions in ParaView can be converted to 3D surface representations first by using the “Cell to Point Data” filter, and then applying the “Warp by Scalar” filter.
Take-Away Messages
- PDE-constrained optimization does not need to be intimidating!
- PETSc/TAO provides interfaces and algorithms that work with reduced-space formulations.
- PETSc/TAO can compute gradients automatically with finite differencing.
- PETSc data structures are easy to couple with most PDE solvers (e.g., AMReX).
- The adjoint method is ideal for sensitivity analysis in PDE-constrained problems.
- Computational cost is (mostly) independent of the number of optimization variables.
- Some PDE solvers already have the necessary building blocks.
- Possible to take implementation shortcuts in self-adjoint problems.
- PETSc/TAO offers parallel optimization algorithms for large-scale problems.
- Optimization data is duplicated from user-generated PETSc vectors.
- User has full control over parallel distribution and vector type.